

新しい監視ツールとして開発途上の Prometheus 概要と、インストール・設定方法、そして複数サーバのCPUやメモリ情報を参照したり、Docker コンテナ情報の取得方法、そしてアラートの確認の仕方を調べました。実際使い始めるまで少々とまどった所もあり、Prometheus を知りたい方、使いたい方向けに、ここで共有します。
■ Prometheus とは?
Prometheus(プロメテウス)は、オープンソースのサービス監視システムと時系列データベースであり、要は監視ツールです。先月末にバージョン 0.1.0 が公開され、目下開発が進んでいます。開発は、音楽のソーシャル・プラットフォームを展開しているSoundCloud社によって2012年から行われ、数千ものサーバを管理することが目的でした。現在はGitHub上で公開されています。開発言語は Go です。
■ これまでの監視ツールとの違いは?
Prometheus は一般的な監視ツールのように、データの収集、数値の表示、グラフの表示、アラートを出す機能があります。それだけでなく、Prometheus は独自のデータモデルを持ち、クエリ言語を使って時系列データの評価やグラフ化を行えます。
例えば、複数サーバの Load Average 値を 5 秒単位で取得し、それぞれ過去1分間の平均値を求めたり、HTTP応答コード毎に集計したり、変動の激しいネットワーク・トラフィックに対するパーセンタイル値の計算を、それぞれグラフ化したりできます。グラフ化は、標準の exporession browser(エクスプレッション・ブラウザ)やPromDashというダッシュボード化ツールを使います。
この特性から、障害発生時のトラブルシューティングだったり、複数台のサーバやコンテナの情報を監視したい時に力を発揮するのではないでしょうか。これまでの状況把握が、コンソール画面を通し、サーバ内で top や dstat コマンドを使っていたのであれば、ブラウザからアクセスできる Prometheus の GUI を通して視覚的に把握できます。動作には RDBMS を必要としませんし、設定もシンプルなので、似たようなツールを使うよりも導入が手軽です。
このように便利そうな Prometheus ですが、万能ではありません。時系列データの記録に特化しているため、データ保管領域は、Prometheus が動作するサーバ上(のローカル・ディスク)に保管されるだけです。単純にスタンドアローンなソフトウェアとして動作します。信頼性を重視する設計のため、監視環境の分散といった可用性は考慮されていません。また、正確さについても保証していないため、正確に記録をしたいのが目的であれば、他のツールを使うべきである、とサイトには書かれています。
■ Prometheus の構成
Prometheus は複数のプログラム群で構成されたシステムの総称です。実際には、次のようにコンポーネントが分かれています。
- Prometheus Server … Prometheus 本体にあたる機能で、「job」と呼ばれる単位で監視情報や監視先の対象を管理します。HTTP ウェブ・インターフェースと、ローカル・ストレージから構成されています。標準では、自分自身のメトリクスを返します。HTTP インターフェースでは、値やグラフの確認を行う expression ブラウザや、アラート設定状況、自分自身のシステム情報を参照できます。
- exporter … Prometheus サーバが読み取り可能なデータを生成します。標準で、サーバリソース を監視する node_exporter のほか、HAProxy、CloudWatch、Cassandra 向けのものが提供されており、これらはグラフの定義も自動的に行ってくれます。CollectDや、StarsDのほか、Docker 向けのものやlibcontainerから取得するものも公開されています。
- Pushgateway … 短期利用やジョブの情報を管理するために使います。コマンドラインを通して Pushgateway の HTTP API にアクセスするか、クライアント・ライブラリを通して情報を扱い、その情報を Prometheus が参照できるようになります。
- クライアント・ライブラリ … Go 、Python、Ruby、Java の各言語に対応したライブラリが提供されています。
- PromDash … ダッシュボード生成用の Rails アプリケーションです。標準の expression browser とは別に、より視覚的なグラフを取得したい時に使います。
- Alertmanager … アラート管理用です。閾値の定義し、GUI を通してアラート情報を参照できます。まだ開発途上です。

参考:http://prometheus.io/docs/introduction/overview/ の図
例えば、あるサーバの CPU やメモリ情報などを取得したい場合は、node_exporter という名前のエクスポーターを対象サーバに設定し、Prometheus 側で対象となるポートに対して HTTP でデータを取得する必要があります。
■ インストール方法について
Go 言語の開発環境があればソースコードから構築することができます。バイナリは現時点では配付されていません。Docker があればコンテナがあるので簡単に使えます。ここでは両方の方法を紹介します。
■ Docker を使って起動する方法
とりあえず Prometheus を使ってみたいのなら、Docker を使う方が簡単です。標準のポート 9090 をホスト側にも公開します。
# docker run -p 9090:9090 prom/prometheus
このコマンドを実行したあと、http://localhost:9090/ にアクセスすると、Prometheus のダッシュボードが表示されます。後述する設定ファイル prometheus.conf を使いたい場合は、設定用ディレクトリを作り、ファイルをマウントする方法が楽です。
ここでは、「/opt/prometheus/prometheus.conf」を、コンテナ内の「/prometheus.conf」に割り当てて起動します。デフォルトで Prometheus は設定ファイル「/prometheus.conf」を参照し、ファイルがない場合は既定値で起動します。別の場所にファイルを置いた時は「-config.file=」オプションが必要です。
# docker run -p 9090:9090 -v /opt/prometheus/prometheus.conf:/prometheus.conf prom/prometheus -config.file=/prometheus.conf prometheus, version 0.10.0 (branch: master, revision: 5a4fe40) build user: root build date: 20150209-12:20:30 go version: 1.4.1
起動後は「Ctrl+C」で中断します。
Prometheus をデーモンモードで起動したい場合は「-d」オプションをつけます。
# docker run -d -p 9090:9090 -v /opt/prometheus/prometheus.conf:/prometheus.conf prom/prometheus 33f14e02d1111a3281a551abaadc8742a8b2278b9a1eca1ca2cb0a8587a60a14
■ ソースから構築・起動する方法(CentOS6で確認)
必要なのは、Go言語の開発環境、curl、git、gzip、hq(mercurialパッケージに同梱)、sed、xxd(vi同梱)、protc バージョン v.2.5.0 以上、gcc-c++パッケージです。手順はドキュメント通りに進められます。必要なパッケージをセットアップします。
# yum install golang git mercurial gcc-c++
そして、Protocol Buffers (protoc) の安定バージョンをセットアップします。CentOS6 の protobuf-c パッケージに含まれる protoc はバージョン 2.3.0 と古いため、動作条件を満たさないため、ソースコードから構築します。
$ wget -O protobuf-2.6.1.tar.gz https://github.com/google/protobuf/releases/download/v2.6.1/protobuf-2.6.1.tar.gz $ tar xvfz protobuf-2.6.1.tar.gz $ protobuf-2.6.1 $ ./configure $ make $ make check # make install
正常に完了すると、次のようにバージョン情報が確認できます。
$ protoc --version libprotoc 2.6.1
あとは、Prometheus の構築です。GitHub からコードを取得し、ビルドするだけです。
$ git clone https://github.com/prometheus/prometheus.git $ cd prometheus $ make build
ビルドしたディレクトリにバイナリが置かれます。バージョン情報を確認すると、次のように表示されます。
$ ./prometheus --version prometheus, version 0.10.0 (branch: master, revision: fd9ee9b) build user: root@web1.teokure.net build date: 20150210-21:07:00 go version: 1.4
なお、本番環境など、性能を出すためには、「GOMAXPROCS」の設定を行います(※環境によって異なります)。また、設定ファイルのパスは「-config.file=」のオプションで指定できます。
# GOMAXPROCS=4 ./prometheus -config.file=prometheus.conf
■ Prometheus の GUI にアクセスする
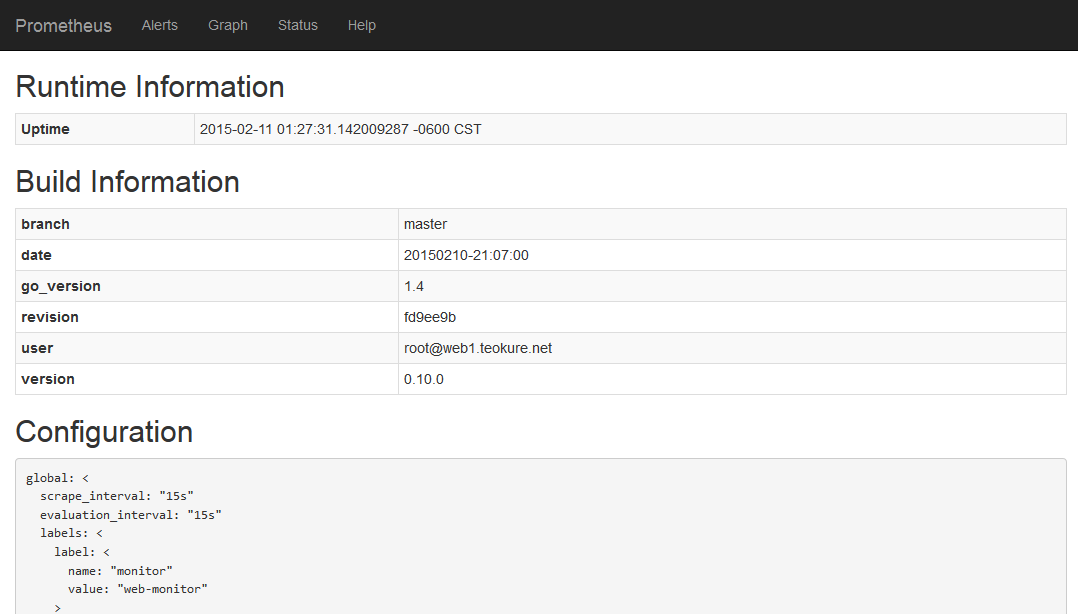
GUI にアクセスするには、ブラウザで http://localhost:9090/ または、IPアドレスやホスト名で対象サーバのポート 9090 を開きます。初期状態では Prometheus の状態を表す「Status」のメニュー内容が表示されます。
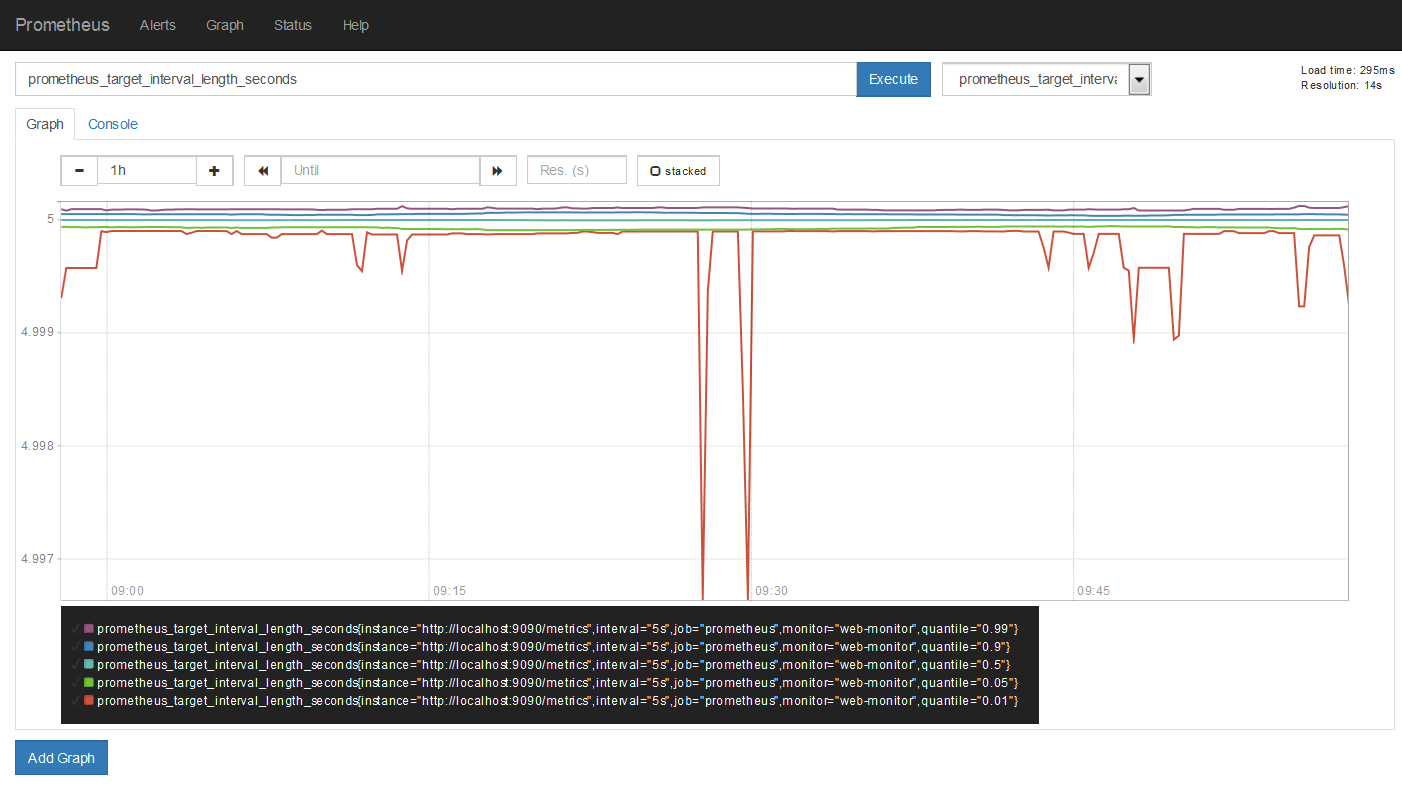
グラフを表示するには「Graph」をクリックし、expression browser(エクスプレッション・ブラウザ)を開きます。「Expression」に表示したいデータの項目を入力するか、「- insert Metric at Corsor -」をクリックして表示したい項目を選びます。「prometheus_target_interval_length_seconds」と入力するか、項目を選択すると、次のように、監視単位の「job」名 prometheus のグラフが出ます。これは、 http://localhost:9090/metrics からデータを取得する感覚をグラフ化したもので、デフォルトでは5秒毎に読み込んでいます。
http://localhost:9100/metrics には、ブラウザから直接アクセスすることもできます。ブラウザで、またはcurl でアクセスすると、次のようにメトリクスが表示されることが確認できます。
# HELP http_request_duration_microseconds The HTTP request latencies in microseconds.
# TYPE http_request_duration_microseconds summary
http_request_duration_microseconds{handler="prometheus",quantile="0.5"} 0
http_request_duration_microseconds{handler="prometheus",quantile="0.9"} 0
http_request_duration_microseconds{handler="prometheus",quantile="0.99"} 0
http_request_duration_microseconds_sum{handler="prometheus"} 0
http_request_duration_microseconds_count{handler="prometheus"} 0
# HELP http_request_size_bytes The HTTP request sizes in bytes.
# TYPE http_request_size_bytes summary
(略)
■設定ファイルの書き方
このように Prometheus の情報が表示されるのは、初期値の設定ファイルが「prometehus」という名前のジョブを定義しているからです。Prometheus 起動時に、監視名や監視間隔を変えたい時は「prometheus.conf」等のファイルを作成し、それを起動時に読み込みます。
global: {
scrape_interval: "15s"
evaluation_interval: "15s"
labels: {
label: {
name: "monitor"
value: "web-monitor"
}
}
}
job: {
name: "prometheus"
scrape_interval: "10s"
target_group: {
target: "http://localhost:9090/metrics"
}
}
「global」は全体の標準となる設定で、ここではデータ取得間隔(scrape_interval)・計算用の間隔(evaluation_interval)を「15s」(15秒)としています。また、「name」や「value」は任意のものを設定できます。
「job」に、どのようなジョブがあるかを記述するものです。デフォルトで使える「prometheus」は、自分自身の統計情報をターゲット「http://localhost:9090/metrics」から取得します。「prometheus」というジョブ名は固定で、変更できません。他のサーバ上のデータを取得したい場合は「localhost」の箇所をIPアドレス等に書き換えます。そして、ここでも「scrape_interval」を指定し、全体の設定を上書きすることもできます。
ファイルを作成後、起動時に「-config.file=」オプションで指定してから起動します。
$ ./prometheus -config.file=prometheus.conf
さて、見える情報がこれだけだと面白くありませんよね。そこで、実用的なサーバのリソースを取得してみます。
■ node exporter でサーバのリソースを取得・表示する
CPUやメモリ、ネットワーク使用状況などサーバのリソース情報を取得するには「node」という名前の「exporter」をサーバに設定し、Prometheus 側で対象の exporter からデータの取得する設定をします。
「exporter」とは、Prometheus サーバが HTTP 経由で参照できるように、データ形式の定義と値を返すためのプログラムです。標準でいくつかのプログラムが提供されていますが、ここでは「node」という名前の exporter を使い、サーバのリソース状況を表示してみます。
まず、データを取得したいサーバに node_exporter のバイナリをセットアップします。まだバイナリが配付されていないため、Go 言語の開発環境で構築する必要があります。
$ git clone https://github.com/prometheus/node_exporter.git $ cd node_exporter $ make $ ./node_exporter
問題無ければ、ポート「9100」を通して対象サーバの情報が取得できます。ブラウザから http://localhost:9100/metrics にアクセスすると、様々なリソース情報がテキスト情報として参照できることが分かりります。
次に Prometheus の設定ファイル prometheus.conf 等で、ジョブを追加します。ジョブ名「node」は固定であり、変更できません。「scrape_interval」は任意の時間を指定できます。そして、先ほど node_exporter を稼働した URL を「target:」に指定します。
job: {
name: "node"
scrape_interval: "5s"
target_group: {
target: "http://localhost:9100/metrics"
}
}
複数のサーバが監視対象の場合は、「target_group:」の中に複数の target を記述します。
target_group: {
target: "http://192.168.39.2:9100/metrics"
target: "http://192.168.39.3:9100/metrics"
}
Prometheus を再起動して暫くすると、データの収集が始まります。
ここでは Load Average を表示してみましょう。ブラウザで GUI にアクセスし「Graph」をクリックします。「 – Insert Metirc at Cursor -」をクリックすると、「node」で始まる情報が追加されていることが分かりります。ここでは1分間の Load Average を表す「node_load1」を選ぶか、テキスト入力フォームに直接入力して「Execute」を押すとグラフが表示されます。
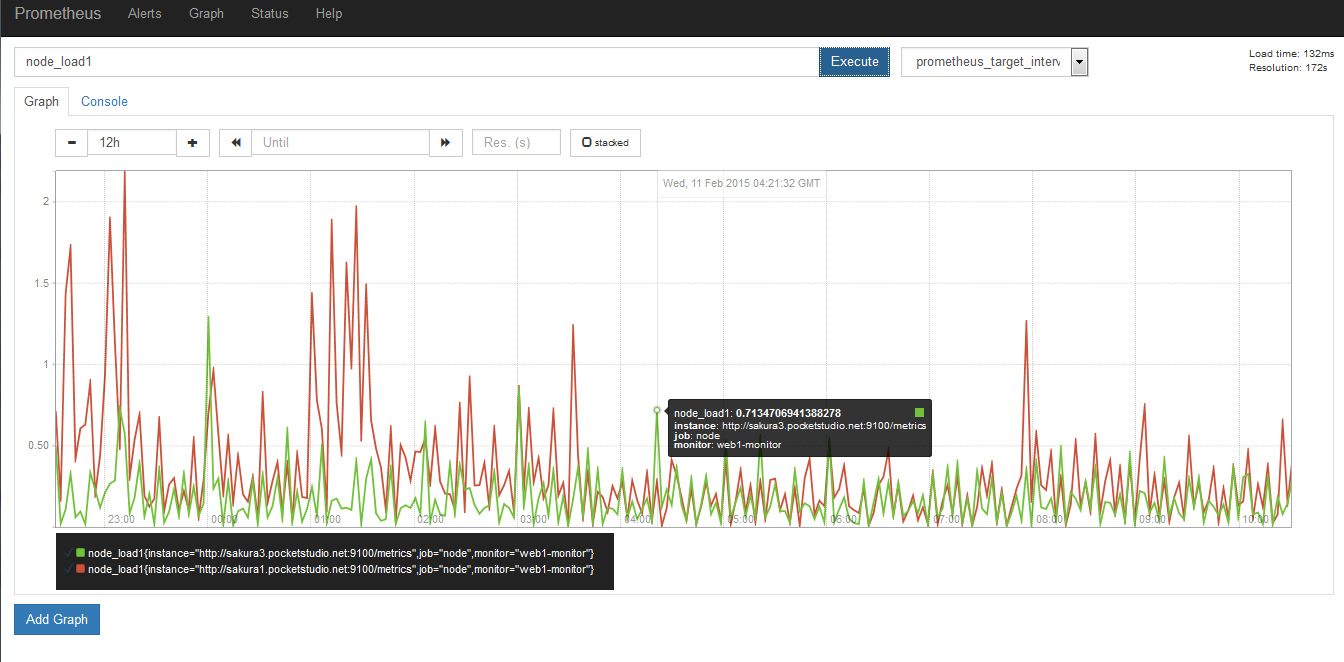
特に何も指定しなければ、取得したデータの情報が表示されます。監視間隔が短いと、少々見づらいです。そこでクエリ言語を使ってデータを加工します。フォームには次のように入力します。
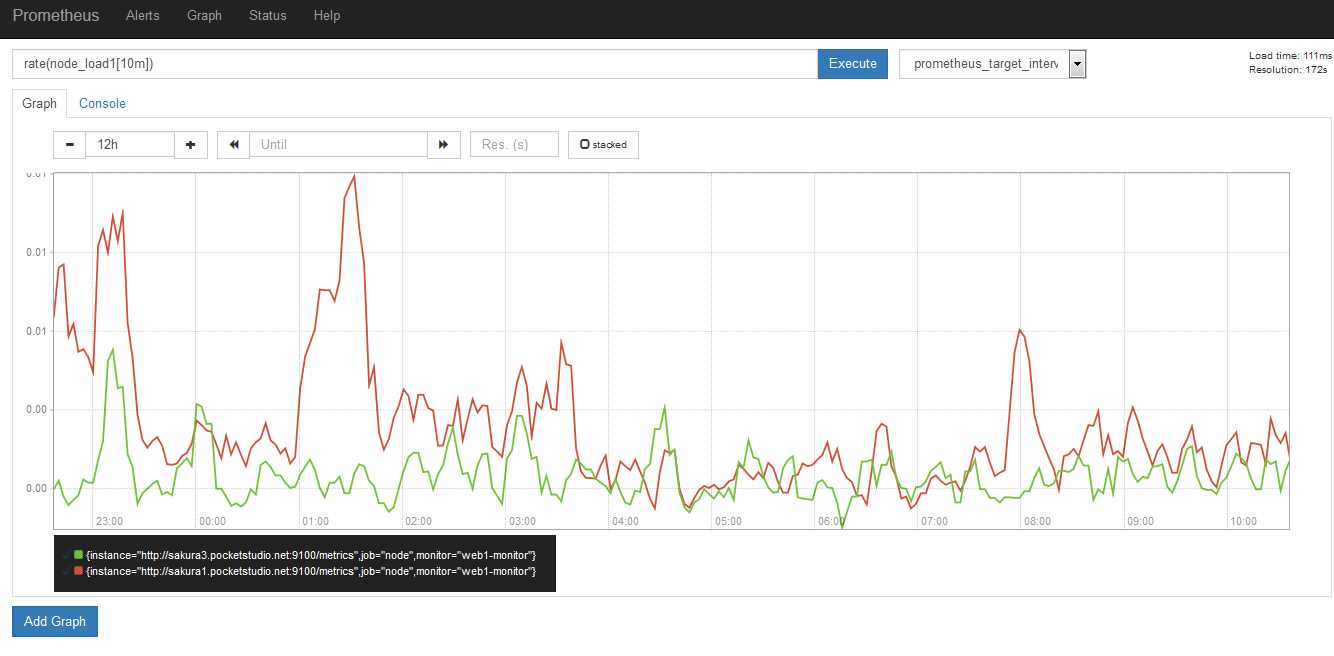
rate(node_load1[10m])
これは「node_load1」のデータを10分間の平均値のグラフに集計しなおすという内容です。グラフを観てみると、先ほどより傾向が分かりりやすくなりました。このほかにも様々なクエリ言語(query language)の文法が用意されています。
もう1つ、node exporter にはサーバのリソース情報を取得するための画面が提供されています。ブラウザから「http://localhost:9090/consoles/node.html」のように URL を手入力すると、認識しているノードの情報や状態が一覧表示されます。

ホスト名をクリックすると、対象ホストの詳細情報が表示されます。データを表示する期間や、自動リロードのタイミングを、この画面上で設定することができます。

■ Docker コンテナの情報を取得する exporter
Docker の情報を取得する時は、「container_exporter」を使います。これを使えば、それぞれのコンテナがどれだけ CPU やメモリ・I/O 等のリソースを使っているかや、その合計を視覚的かつ動的に把握できます。コンテナを追加・削除しても、設定ファイルを書き換える必要はありません。専用の exporter を起動しておくだけです。
ここでは CentOS6 で使う場合の例を紹介します。データを取得するには、専用のコンテナを使う方法が簡単です。コンテナを起動するには、次のようにします。
# docker run -p 8080:8080 -v /cgroup:/cgroup \ -v /var/run/docker.sock:/var/run/docker.sock prom/container-exporter
デーモンとして常駐したい場合は、「docker run」に「-d」オプションをつけると管理が容易になります。正常に起動したあとは、ブラウザで http://localhost:8080/metrics にアクセスします。ここに Docker に関する文字列が表示されれば作業得完了です。
今回紹介するのは cgroup の情報を集計するものですが、libcontainer を使って取得するものも公開されています。
次に Prometheus 側の prometheus.conf 等に、ジョブ「container-exporter」の情報を定義します。
job: {
name: "container-exporter"
scrape_interval: "5s"
target_group: {
target: "http://localhost:8080/metrics"
}
}
あとは Prometheus 再起動後に設定が反映されます。GUI で「Graph」にアクセスし、「container_memory_usage_bytes」と入力すると、各コンテナ毎のメモリ使用率が表示できます。

その他にも、コンテナ毎の CPU や I/O が確認できます。マウスカーソルをグラフ上に移動すると、詳細名やコンテナ名が表示されるので、1つのサーバ内でどのコンテナの使用率が高いかどうか、効率的に使っているかどうかなど稼働状況の把握に役立つことが期待できます。
■ Alert 機能を試してみる
「Alaer manager」を使い、アラートの閾値を設定できます。現時点では開発段階ですが、アラートの超過は設定できます。この機能を試すには、ソースからビルドします。
$ git clone git@github.com:prometheus/alertmanager.git $ cd alertmanager $ make
実行後、バイナリが作成するだけで実行可能です。標準ではポート 9093 を使用しますが、「-web.listen-address=」オプションを使いポート番号を変更することもできます。
$ ./alertmanager alertmanager, version 25b925c (master) build user: zem@sakura1.pocketstudio.net build date: 20150211-16:05:31 go version: 1.4.1
この alertmanager 自身がブラウザから表示可能な GUI を備えています。起動に成功すると、次のような画面が http://localhost:9093/ にアクセスすると表示されます。

ここには何も表示されていませんが、またアラートの定義を行っていないからです。alartmanager 自身は、Promehteus サーバからアラート情報を受け取り、画面に表示したりメールを送信したりします。
Promethes サーバ側では prometheus.conf にアラートの記述を追加します。まず、「global:」の中で「rule_file」を定義します。以下は記述例です。
global: {
scrape_interval: "15s"
evaluation_interval: "15s"
labels: {
label: {
name: "monitor"
value: "web-monitor"
}
}
rule_file: "alerts.rules"
}
次に、「alerts.rules」ファイルを作成し、中に次のような記述を行います。
ALERT NodeHighLoadaverage
IF rate(node_load1[10s]) > 0.01
FOR 10s
WITH {}
SUMMARY "High load average on {{$labels.instance}}"
DESCRIPTION "{{$labels.instance}} has a high load average above 10s (current value: {{$value}})"
意味は「10秒間あたりの1分間の平均 load averageが、10秒間 0.01 を超えた時にアラートを出す」という内容です。テスト的な記述であり、実際には様々な条件が設定できます。
次に、prometehus を起動する際、先の alertmanager を明示します。
$ ./prometheus -config.file=prometheus.conf \ -alertmanager.url=http://192.168.39.3:9093
あとは、負荷の高い状況を作ると、次のようにアラート情報が alertmaager の GUI 画面に表示されることが分かりります。

■おや、グラフの時刻の様子が・・・
グラフに表示される時刻はUTCで固定されています。日本標準時 JST に変更することはできません。このあたりは FAQ に掲載されているほか、GitHub の Issue にも上げられています。理由は、開発者の考えとして、データ自身は UTC ですが、UI 側でローカルタイムに変更してはどうでしょうかという提案がなされてます。
■最後に
このように、Promtheus を動かすのは比較的簡単なため、興味をお持ちになりましたら、新感覚なツールを試していただければと思います。
おおまかな使い方を紹介しましたが、Prometheus は他にも複雑なことができます。まだバージョンは v.0.1.0 と開発途上。それでも、提供されている機能は、監視や運用にとって、これまでの top や dstat を使う方法とは、別の可能性を感じさせてくれます。データの保全性はありませんので、現状把握やトラブルシュートに活躍するのではないかと思います。また、監視ツールとしての Zabbix や Sensu、Nagios、Munin 等とは監視の対象や目的が違いますので、おそらく併用する形になるのではと考えています。
■参考
- http://prometheus.io
- Backstage Blog – Prometheus: Monitoring at SoundCloud – SoundCloud Developers
- Monitor Docker Containers with Prometheus
Related posts:
- tcptrackでトラフィックや通信状況をリアルタイム把握
- Muninを(^ω^)ペロペロするスクリプトを書いてみた(muniinwalk/muninget)
- 【メモ】SmokePingでlatency視覚化(2) DNS&HTTP応答編
- 【Debian/Ubuntu】Munin 2.0 をソースor バイナリ(.deb)でセットアップ
- これから始めるZabbix Sender(1) サーバにデータを送るには?
- RHEL5にGraphiteをセットアップ
- Docker Machine 0.3 の新機能、generic ドライバと scp を試す
- ZABBIXの通知メールをスレッド化してみる
- 古い環境を pmmn(A Poor Man’s Munin Node)で監視
- Weave Scopeでコンテナ構成をリアルタイム視覚化

ペロペロするスクリプトを書いてみた(muniinwalk/muninget)")
 DNS&HTTP応答編")
でセットアップ")
 サーバにデータを送るには?")



で監視")
